Предисловие
На связи снова чашка с кодом! ) Спустя достаточно длительный перерыв в творчестве настало время снова взяться за перо. Сегодня я бы хотел рассказать о том, как при помощи реализации CQRS паттерна при использовании Spring Data Jpa можно бороться с недостатками использования ORM.
Каждый "уважающий себя" backend-разработчик сталкивался с использованием технологии ORM или ORM-like при разработке бэкенда. Однако при использовании подобных технологий в течение длительного времени и в достаточно крупных проектах становятся очевидны недостатки ORM, такие как:
1. Неочевидное формирование запросов к бд, зачастую приводящее к генерации излишнего количества запросов, что провоцирует известную N+1 проблему.
2. Сложность или невозможность частичного извлечения данных из бд, когда требуется вернуть клиенту лишь часть полей исходной модели. Наиболее часто встречающийся пример: отображение списка сущностей таких как статьи, каждая из которых обладает большим по объему контентом.
3. Необходимость преобразований из модели хранения в доменную модель при извлечении данных. Неочевидный недостаток, вытекающий из того, что нередко доменная модель по своей структуре отличается от модели хранения (например, в случае применения денормализации данных на уровне хранения).
Каждый из упомянутых выше недостатков сводится к головной боли разработчика о сохранении производительности эндпоинтов в случае, когда модели начинают все больше и больше разрастаться по своему объему.
CQRS паттерн
Название паттерна расшифровывается как Command and Query Responsibility Segregation (разделение ответственности между командами и запросами). В общем случае, CQRS паттерн о разделении моделей для записи и для чтения, а также самих хранилищ.
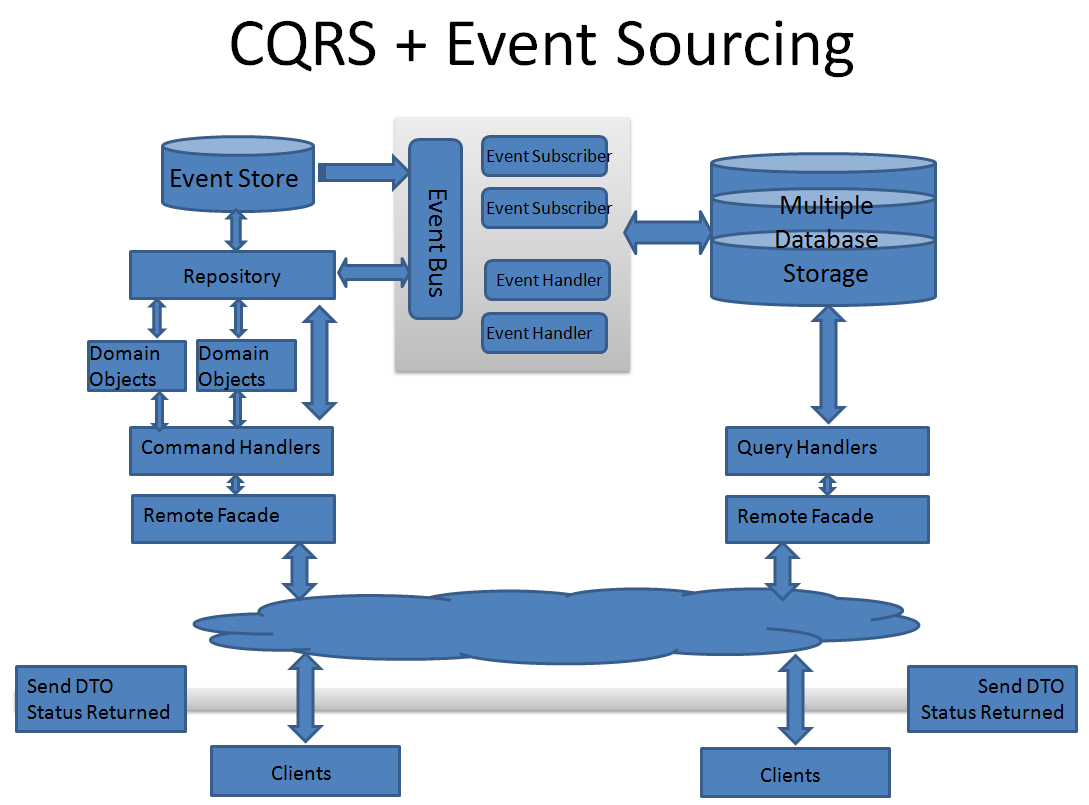
Страшная картинка выше взята вот отсюда: https://bool.dev/blog/detail/pattern-cqrs-i-event-sourcing
Как видно из изображения мы имеем Event Store (бд, в которую пишем) и модели для записи (Domain Objects) с одной стороны и Database Storage (реплика, из которой читаем) и модели для чтения с другой стороны. При этом важно упомянуть, что паттерн CQRS основан на свойстве операций чтения не изменять данные. Действительно, в подавляющем большинстве случаев при чтении данных мы достаем их из бд "как есть" и не подвергаем никаким мутациям. Следовательно, если предположить, что для данных хранящихся в бд ограничения целостности бизнес-логики выполняются, то для извлеченных данных это также справедливо. По этой причине при извлечении данных нам нет необходимости строить сложные доменные модели и выполнять проверки бизнес-правил. При изменении данных - другое дело. Нам уже требуются наши огромные модели и вся та сложная логика, которая проверяет согласованность данных и выполняет проверки бизнес-правил.
Использование реплик бд для операций чтения призвано увеличить производительность доступа к данным за счет выделения отдельных вычислительных ресурсов под базы данных, реализующих доступ на чтение. Вот уже на этом месте у читателя могут встать волосы дыбом на затылке при мысле о том, что для решения обозначенных в начале статьи проблем ORM автор предлагает поднимать реплики базы данных... =)
Однако спешу вас успокоить! Это лишь общая концепция паттерна, на практике же можно применять его и без создания реплик баз данных.
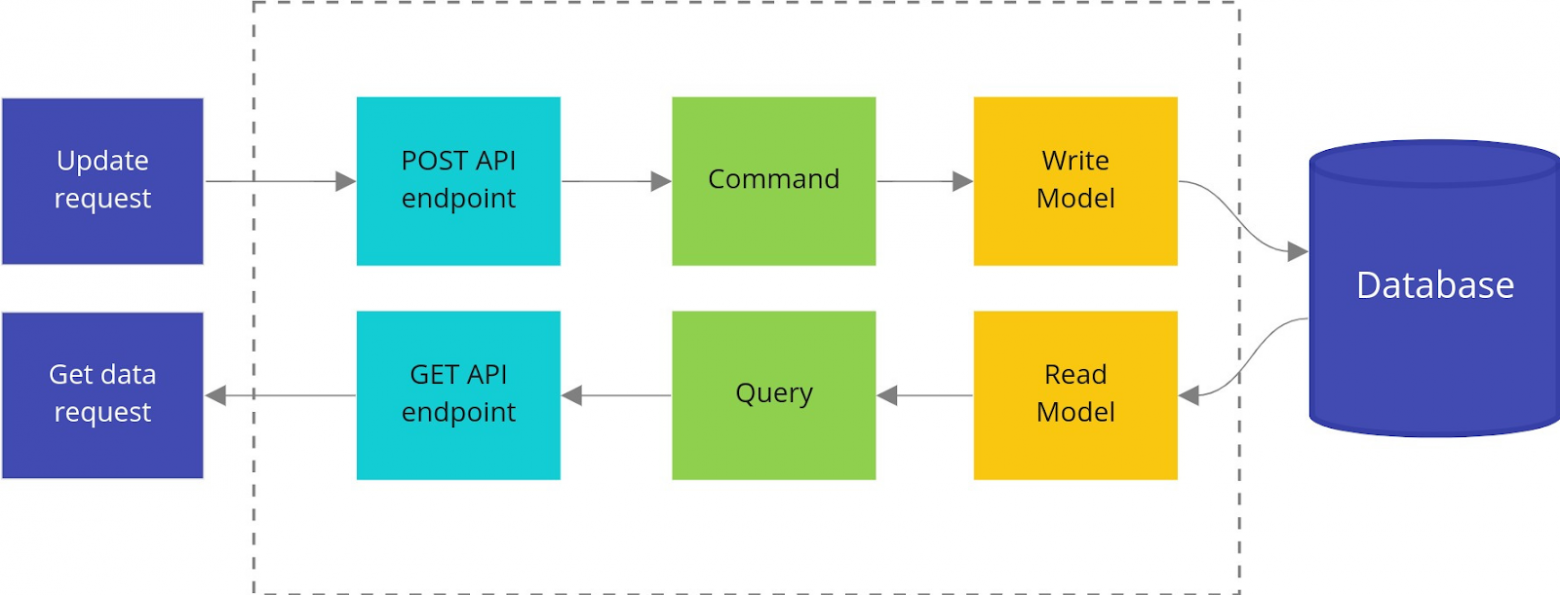
Уже не такая страшная картинка взята вот отсюда: https://habr.com/ru/articles/543828/
Что если мы не будем разделять бд для записи и для чтения, но разделим модели и логику? В таком случае мы получим архитектуру бэкенда, похожую на ту, что изображена на рисунке выше. Зеленые компоненты "команда" и "запрос" представляют собой модули, содержащие бизнес-логику. Команда призвана конструировать объекты доменной модели, выполнять сложные проверки бизнес-правил и другую магия кровавого enterprise-а. Запрос же наоборот - призван заниматься извлечением данных без (или почти без) каких-либо преобразований и сложной логики с использованием отдельной модели данных для чтения.
Преимущества:
- разделение логики между отдельными классами команд и запросов - уменьшает объем кода, упрощает его сопровождение и доработку.
- логика чтения данных изолирована от логики изменения данных - проще контролировать количество запросов, генерируемых ORM (но об этом подробнее в разделе про реализацию).
- наличие отдельной модели данных для чтения позволяет добиться желаемой гибкости при частичном извлечении данных.
- модель для чтения данных может полностью совпадать с моделью ответа API бэкенда, так как она не нуждается в проверке ограничений целостности - повышение производительности за счет уменьшения количества преобразований данных между различными слоями моделей.
Недостатки:
- требует от команды разработчиков большей эрудиции, так как CQRS паттерн и его реализации нужны и в принципе применяются нечасто.
- сложность паттерна, особенно при реализации разделение баз данных для чтения и записи.
- вынужденное дублирование кода между моделями записи и чтения.
- необходимость реализации отдельных операций чтения данных для команд - им все еще нужно извлекать данные из базы данных для своей работы.
Думаю, настала пора наконец перейти от теории к практике!
Реализация CQRS
Теперь обсудим, как применять данный паттерн на практике при написании бэкенда на Spring + Kotlin. Для начала определим базовую структуру пакетов, которую автор рекомендует к использованию:
./root_package
-- api
-- | http
-- | <context-name>
-- | SomeController.kt
-- | requests.kt
-- | views.kt
-- domain
-- | model
-- | <context-name>
-- | SomeModel.kt
-- | service
-- | <context-name>
-- | actions
-- | CreateAction.kt
-- | UpdateAction.kt
-- | DeleteAction.kt
-- | filters
-- | GetByIdFilter.kt
-- | GetPageByNameFilter.kt
-- | SomeService.kt
-- infrastructure
-- | storage
-- | <context-name>
-- | model
-- | SomeEntity.kt
-- | repo
-- | SomeRepository.kt
При использовании такой структуры:
- <context-name> обозначает название некоторого бизнес-контекста
- модели для чтения располагаются в api/http/<context-name>/views.kt
- модели для записи (доменные модели) находятся в domain/model/<context-name>/
- классы команд хранятся в domain/service/<context-name>/actions/
- классы запросов можно найти в domain/service/<context-name>/filters/
- названия actions и filters для команд и запросов выбраны чисто на вкус автор - называйте как хотите. Но будьте осторожны! Неискушенный коллега может ошибочно посчитать, что в пакете commands располагаются реализации известного одноименного паттерна.
- модели для записи (модели хранения данных) находятся в infrastructure/storage/<context-name>/model/
- репозитории располагаются в infrastructure/storage/<context-name>/repo/
Для уменьшения количества полотен кода в статье практически все модели намерено упущены! Автор абсолютно уверен, что раз вы до сих пор читаете эту статью, то описывать модели вы точно умеете.
В примерах ниже приведены выдержки кода одного из некоммерческих проектов, с которыми довелось работать автору статьи, посвещенному созданию платформы для онлайн-образования. Более предметно, данные полотно кода принадлежат микросервису, ответственному за хранение структуры и контента онлайн-курсов.
@Service
class CreateCourseAction(
private val courseRepository: CourseRepository,
) {
@Transactional(isolation = Isolation.REPEATABLE_READ)
operator fun invoke(request: CreateCourseRequest): Course {
val existedCourseWithSuchName = courseRepository.findByName(request.name)
if (existedCourseWithSuchName != null) {
throw AlreadyExistException()
}
val courseAuthor = getRequestAuthorUserInfo()
val courseAuthorId = courseAuthor.id
val course = createCourse(request, courseAuthorId)
createCourseExample(course, courseAuthorId)
log.info("New Course has been created. Name: ${course.name}, id: ${course.id}. Author: ${courseAuthor.username}")
return course
}
private fun createCourse(request: CreateCourseRequest, courseAuthorId: String): Course = courseRepository.save(
Course(
id = 0L,
name = request.name,
description = request.description,
logo = request.logo,
archiveInfo = ArchiveInfo.notArchived(),
publicationInfo = PublicationInfo.notPublished(),
modificationInfo = ModificationInfo.creationInfo(courseAuthorId),
).toEntity()
).toModel()
}
В полотне выше приведен исходный код класса-команды CreateCourseAction, ответственного за создание новой сущности курса. Как можно видеть, данный класс оперирует моделью Course, относящейся к моделям для записи. Также внимательный читатель заметит, что основная логика команды размещена в перегруженном операторе invoke (далее вы увидите для чего это используется).
@Service
class GetCoursePageFilteredFilter(
private val courseRepository: CourseRepository,
) {
operator fun invoke(
request: CoursesFilteredRequest,
pageParams: PageParams
): Page<CourseTableInfo> = courseRepository
.findAllFiltered(
name = request.filters.name,
isPublished = request.filters.isPublished,
isArchived = request.filters.isArchived,
pageable = PageRequest.of(
pageParams.pageNumber,
pageParams.pageSize,
Sort.by(Sort.Direction.ASC, "name")
)
)
}
В данном фрагменте приведен исходный код класса-запроса GetCoursePageFilteredFilter, ответственного за извлечение пагинированного списка существующих курсов. При этом данный класс оперирует уже не моделью Course (для записи), а моделью CourseTableInfo (для чтения), которая представляет собой выборку полей оригинальной модели Course (например, отсутствует поле description).
Ниже приведен исходный код запроса findAllFiltered из репозитория CourseRepository
@Query(
"""
SELECT new com.newdex.services.course.domain.course.model.CourseTableInfo(
c.id,
c.name,
c.logo,
c.publicationDate,
c.archiveDate
)
FROM CourseEntity c
WHERE
(COALESCE(:name, NULL) IS NULL OR LOWER(c.name) LIKE CONCAT('%', LOWER(:name), '%'))
AND (
COALESCE(:isPublished, NULL) IS NULL
OR (:isPublished = TRUE AND c.publicationDate != CAST('10000-01-01 00:00:00' AS TIMESTAMP))
OR (:isPublished = FALSE AND c.publicationDate = CAST('10000-01-01 00:00:00' AS TIMESTAMP))
)
AND (
COALESCE(:isArchived, NULL) IS NULL
OR (:isArchived = TRUE AND c.archiveDate != CAST('10000-01-01 00:00:00' AS TIMESTAMP))
OR (:isArchived = FALSE AND c.archiveDate = CAST('10000-01-01 00:00:00' AS TIMESTAMP))
)
"""
)
fun findAllFiltered(
name: String?,
isPublished: Boolean?,
isArchived: Boolean?,
pageable: Pageable
): Page<CourseTableInfo>
Обратите внимание, что в данном запросе используется механизм проекций библиотеки Spring Data Jpa, благодаря которому становится возможным возвращать из методов репозиториев не классы сущностей, а классы их проекций. Подробнее о проекциях можно почитать в официальной документации: https://docs.spring.io/spring-data/jpa/reference/repositories/projections.html. Кроме того, конечно же, используется самописный JPQL запрос, благодаря чему достигается высокая степень контроля за запросами, которые генерирует ORM при выполнении метода.
Теперь посмотрим на исходных код сервиса CourseStructureService.
@Service
class CourseStructureService(
val createCourse: CreateCourseAction,
val updateCourse: UpdateCourseAction,
val publishCourse: PublishCourseAction,
val archiveCourse: ArchiveCourseAction,
val getCourseById: GetCourseByIdFilter,
val getCoursePageFiltered: GetCoursePageFilteredFilter,
val createChapter: CreateChapterAction,
val updateChapter: UpdateChapterAction,
val deleteChapter: DeleteChapterAction,
val getChapterById: GetChapterByIdFilter,
val getChaptersAllByCourseId: GetChaptersAllByCourseIdFilter,
val createModule: CreateModuleAction,
val updateModule: UpdateModuleAction,
val deleteModule: DeleteModuleAction,
val getModuleById: GetModuleByIdFilter,
val getModulesPageByChapterId: GetModulesPageByChapterIdFilter,
val getLessonsPageByModuleId: GetLessonsPageByModuleIdFilter,
)
Ничего себе какой кроха! Как можно видеть весь класс состоит всего лишь из публичных полей... как же так??? ))
@RestController
@RequestMapping("/api/v1/courses")
class CourseStructureController(
private val courseStructureService: CourseStructureService,
) {
@PostMapping
@ResponseStatus(HttpStatus.CREATED)
fun createCourse(
@RequestBody @Validated request: CreateCourseRequest
): CourseShortView = courseStructureService.createCourse(request).toShortView()
@PutMapping("/{courseId}")
fun updateCourse(
@PathVariable("courseId") courseId: Long,
@RequestBody @Validated request: UpdateCourseRequest,
): CourseShortView = courseStructureService.updateCourse(
id = courseId,
request = request,
).toShortView()
@GetMapping("/{courseId}")
fun getCourseById(
@PathVariable("courseId") courseId: Long,
): Course = courseStructureService.getCourseById.withCourseVisibilityCheck(courseId)
@PostMapping("/{courseId}/archive")
fun archiveCourse(
@PathVariable("courseId") courseId: Long,
): Unit = courseStructureService.archiveCourse(courseId)
@PostMapping("/{courseId}/publish")
fun publishCourse(
@PathVariable("courseId") courseId: Long,
): Unit = courseStructureService.publishCourse(courseId)
@PostMapping("/filtered")
fun getCoursePageFiltered(
@Validated pageParams: PageParams,
@Validated @RequestBody request: CoursesFilteredRequest,
): PageView<CourseTableInfo> = courseStructureService.getCoursePageFiltered(
request = request,
pageParams = pageParams
).toView()
}
Согласитесь, исходный код контроллера, использующего сервис, который мы только что видели, внешне выглядит так, будто бы использует совершенно "нормальный", "обычный" сервис? ) Благодаря тому, что мы, во-первых, в классах команд и запросов переопределили оператор invoke, и, во-вторых, заименовали поля с командами и запросами в сервисе так, будто бы это методы, складывается впечатление, что мы как будто бы "включили" в сервис n-ое количество методов за счет композиции команд и запросов. Теперь представьте, каким большим бы был размер класса сервиса, если бы мы "развернули все эти методы"? При подобной реализации CQRS паттерна мы еще и существенно повысили читаемость наших сервисов!
Важно отметить, что для переиспользования кода, например, одной команды другой команды нам достаточно объявить зависимость одной команды на другой команде и "вызвать" команду. Таким же образом, можно в командах переиспользовать и запросы, если в этом есть необходимость.
Вместо выводов
В заключении вернемся к исходным недостаткам использования ORM, которые были обозначены в начале статье. Как же использование CQRS паттерна позволяет нам бороться с ними?
1. Неочевидное формирование запросов к бд - с этим недостатком, увы, полностью справиться не получилось. Однако благодаря тому, что мы вынесли логику запросов в отдельные классы и пишем вручную JPQL запросы, извлекающие не Entity, а проекции - мы существенно увеличили наглядность в плане количества запросов к базе данных. К тому же, при таком подходе невозможно наступить на классическую граблю с фетчингом lazy полей в виде отдельных запросов, так как мы не используем Entity.
2. Сложность или невозможность частичного извлечения данных из бд - хотя механизм проекций в Spring Data Jpa далек от идеала и с ним сложно реализовать вложенные проекции - это уже существенное облегчение задачи частичного извлечения данных. Если же случай "настолько запущенный", что, используя проекции, не удается добиться желаемого, всегда можно прибегнуть к старым-добрым NamedJdbcTemplate-ам.
3. Необходимость преобразований из модели хранения в доменную модель при извлечении данных - полностью побеждено! Теперь мы можем прямиком из репозиториев возвращать нужные модели, которые в последствие будут сериализованы в ответ нашего бэкенда. При подобном подходе с формированием именно нужных нам select-ов нам становятся не нужны "маппинги", "преобразования", "переливания данных из одной модели в другую".
К сожалению, опубликовать полный пример исходного кода не могу, так как репозиторий проекта приватный, однако надеюсь, что вам хватит и того, что поместилось в текст статьи =)
Желаю продуктивного coding time!

