
Введение
В современном интернете очень популярны сервисы, передающие данные в потоковом режиме. Например, на ум сразу приходит всеми известный видео сервис - YouTube, а также различные музыкальные сервисы, такие как Yandex Музыка и другие. Потоковая передача данных или streaming - это способ передачи данных, при котором данные передаются небольшими порциями (chunks) в рамках нескольких или множества отдельных запросов. Такой способ передачи позволяет передавать клиентским приложениям файлы огромных размеров (по частям), сохраняя при это высокую производительность и отзывчивость. С помощью этой техники во многих онлайн плеерах поддерживается быстрый старт воспроизведения, а также быстрое перемещение на нужный сегмент видео или аудио.
В этой статье мы рассмотрим создание простого REST API бэкэнд-приложения для потоковой передачи видео на языке программирования Kotlin с использованием технологий Spring Boot, MinIO и PostgreSQL.
Реализация подобных приложений обычно связано с реализацией поддержки 206-го кода состояния http (206 HTTP Code (Partitial Content)).
Если клиент в ответе получает HTTP 206 Partial Content со статусом success, это указывает на то, что запрос прошел успешно и тело содержит запрошенные диапазоны данных, как описано в заголовке запроса "Range".
Существует несколько вариантов реализации потоковой передачи данных: 1) когда в ответе возвращается только один диапазон данных (заголовок Content-Type выставляется равным типу файла, заголовок Content-Range содержит диапазон фрагмента данных) и 2) когда в ответе возвращается несколько диапазонов данных (заголовок Content-Type задается как multipart/byteranges, и каждый фрагмент охватывает свой один диапазон, с соответствующим описанием Content-Range и Content-Type).
Мы будем реализовывать первый вариант, так как он проще и наиболее часто встречается на практике.
Spring Initializer
И так, давайте приступим к созданию приложения. Для того, чтобы не писать с нуля, не относящийся к бизнес логике базовый код, воспользуемся утилитой Spring Initializer.
В ней я выставил настройки так, как указано на изображениях ниже:
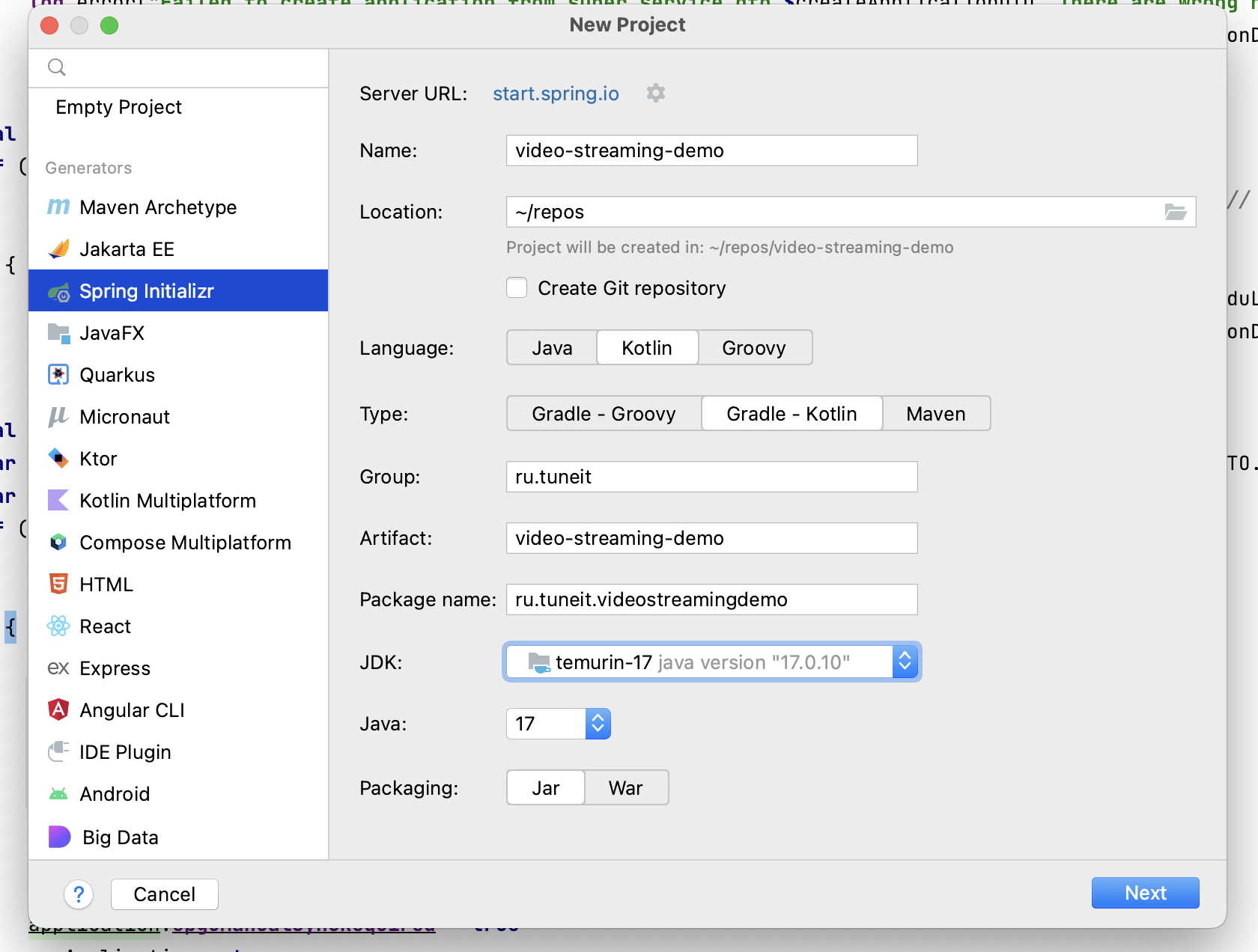
В этой утилите мы можем сразу выбрать необходимые нам зависимости:
Spring Web - для создания контроллеров и эндпоинтов (RESTful API + Apache Tomcat embedded),
PostgreSQL Driver - драйвер для взаимодействия с базой данных PostgreSQL,
Spring Data JPA - для создания слоя взаимодействия с SQL-хранилищем данных (JPA, Spring Data + Hibernate)
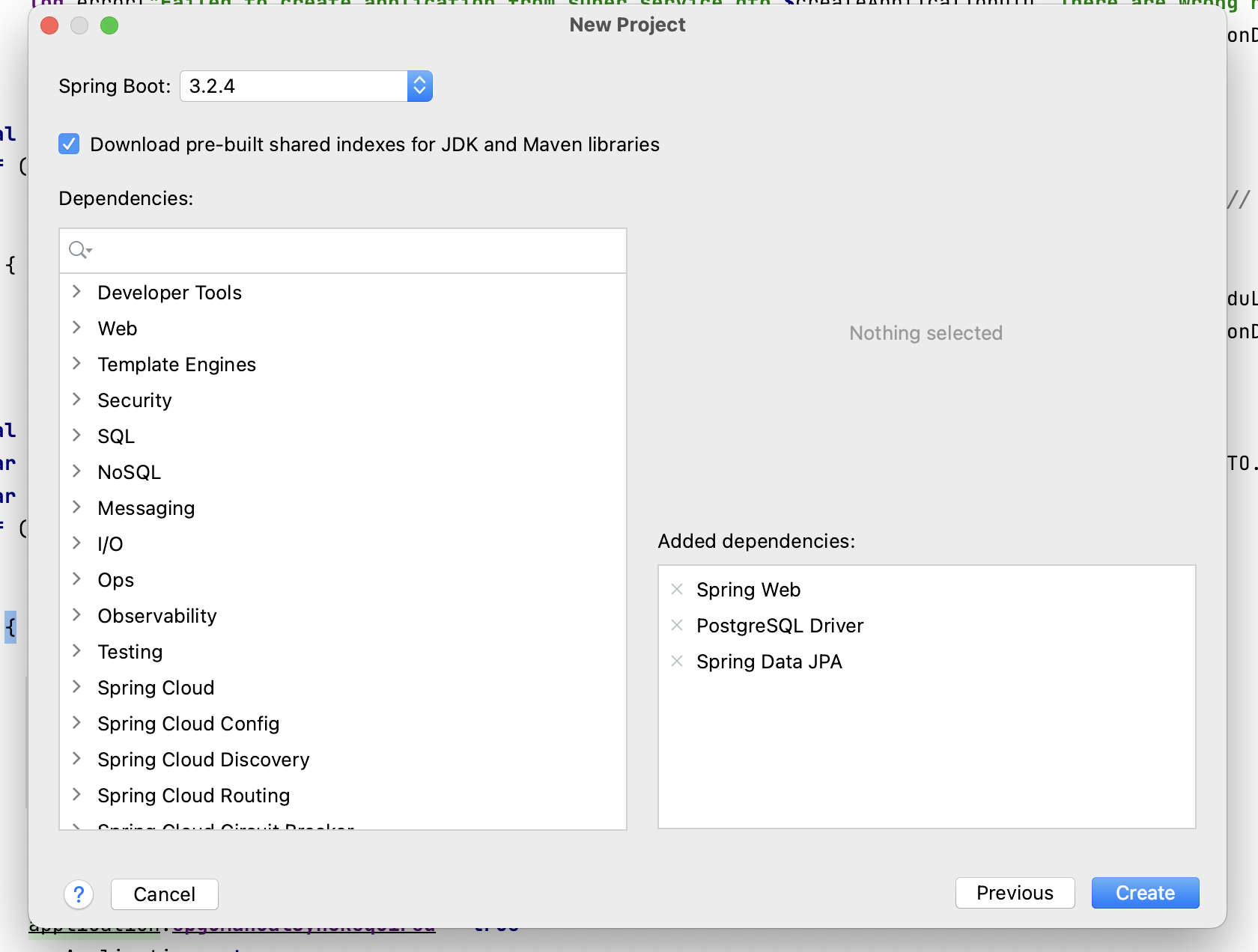
Нам остается нажать кнопку Create и готово! Каркас нашего приложения создан.
По мимо этих зависимостей нам необходима ещё одна для работы с хранилищем объектов Minio :
implementation("io.minio:minio:8.5.9")
Её мы добавляем вручную в файл build.gradle.
В итоге, этот файл у нас имеет следующий вид:
import org.jetbrains.kotlin.gradle.tasks.KotlinCompile
plugins {
id("org.springframework.boot") version "3.2.4"
id("io.spring.dependency-management") version "1.1.4"
kotlin("jvm") version "1.9.23"
kotlin("plugin.spring") version "1.9.23"
kotlin("plugin.jpa") version "1.9.23"
}
group = "ru.tuneit"
version = "0.0.1-SNAPSHOT"
java {
sourceCompatibility = JavaVersion.VERSION_17
}
configurations {
compileOnly {
extendsFrom(configurations.annotationProcessor.get())
}
}
repositories {
mavenCentral()
}
dependencies {
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
implementation("org.springframework.boot:spring-boot-starter-web")
implementation("com.fasterxml.jackson.module:jackson-module-kotlin")
implementation("org.jetbrains.kotlin:kotlin-reflect")
implementation("io.minio:minio:8.5.9")
runtimeOnly("org.postgresql:postgresql")
testImplementation("org.springframework.boot:spring-boot-starter-test")
}
tasks.withType<KotlinCompile> {
kotlinOptions {
freeCompilerArgs += "-Xjsr305=strict"
jvmTarget = "17"
}
}
tasks.withType<Test> {
useJUnitPlatform()
}
Отлично! Переходим к следующему шагу.
Создание docker-compose файла
Один из самых быстрых способов загрузить и запустить необходимые нам внешние сервисы, такие как MinIO и PostgreSQL, - использовать инструмент docker-compose (для его работы необходимо, чтобы у вас был установлен docker).
Вот наш файл docker-compose.yml с настроенными сервисами:
version: '3.8'
services:
postgres:
container_name: "video-streaming-postgres"
image: postgres
ports:
- "5432:5432"
environment:
POSTGRES_USER: test
POSTGRES_PASSWORD: test
POSTGRES_DB: video-streaming
minio:
container_name: "video-streaming-minio"
image: quay.io/minio/minio:RELEASE.2024-04-06T05-26-02Z
command: server --console-address ":9001" /data
ports:
- "9000:9000"
- "9001:9001"
volumes:
- minio-data:/data
environment:
MINIO_ROOT_USER: minio_admin
MINIO_ROOT_PASSWORD: minio_admin
volumes:
minio-data:
driver: local
Чтобы запустить эти сервисы, необходимо выполнить следующую команду в терминале из директории где находится файл docker-compose.yml:
docker-compose up -d
Я использую программу Docker Desktop и после выполнения команды, в этой программе я вижу что были созданы и успешно запущены два наших контейнера:
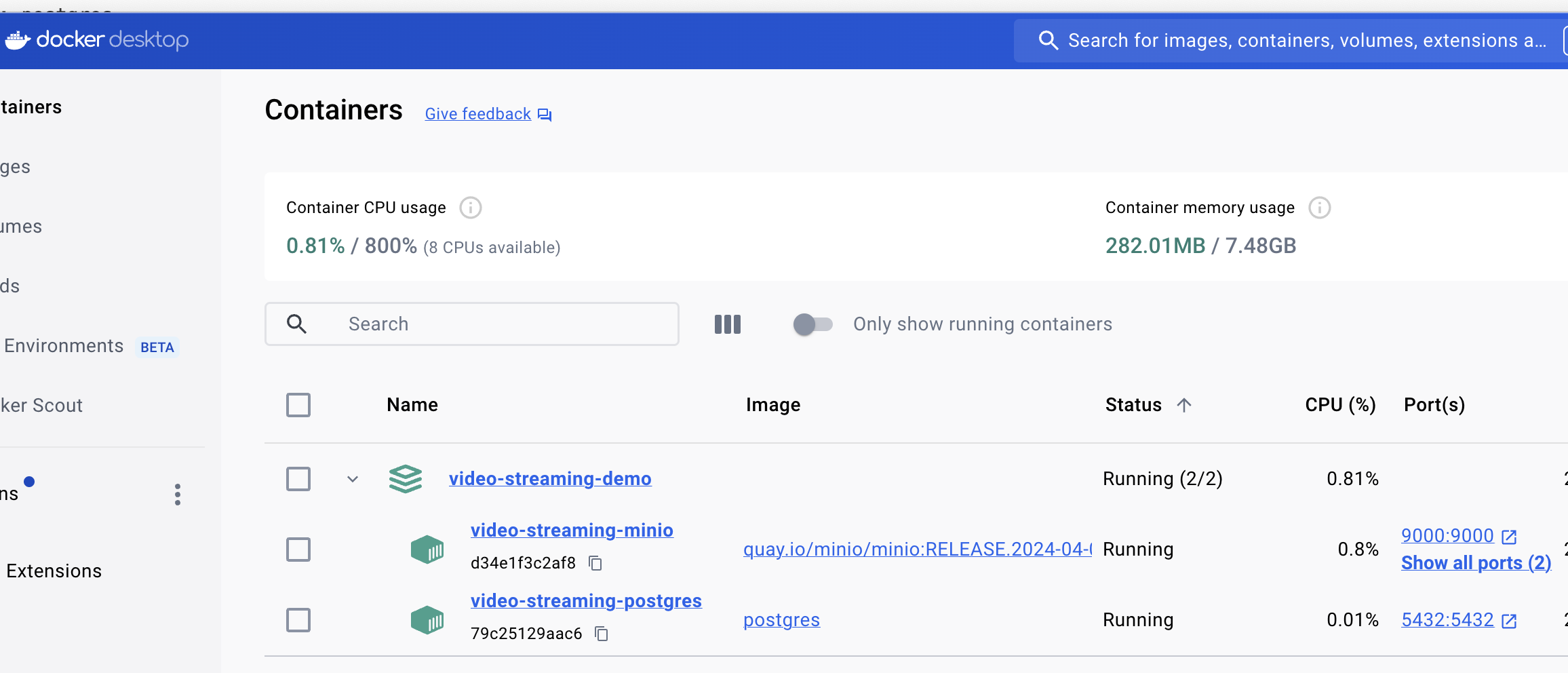
Прекрасно! Каркас приложения создан, внешние сервисы, которые необходимы для работы приложения запущены, теперь переходим к реализации функционала. Начнем с создания модели данных.
Создание модели данных и репозитория
Нам необходима простая модель данных, описывающая метаданные загруженного в наш сервис видео файла. Пусть наша модель будет описывать такие характеристики файла как: название, уникальный идентификатор видео, тип файла, размер содержимого, дата и время загрузки файла в сервис.
Создадим класс для этой модели. Назовем его FileMetadata:
@Table(name = "file_meta")
@Entity
class FileMetadata (
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Id
var id: Long? = null,
var name: String,
var uuid: UUID,
var contentType: String?,
var contentSize: Long,
@CreationTimestamp
var uploadedAt: LocalDateTime
)
С помощью аннотаций @Entity и @Table пометим этот класс как сущность. Он будет связан с таблицей "file_meta" в нашей базе данных.
Для выполнения операций CRUD с этой сущностью, мы будем использовать интерфейс JPA репозитория из фреймворка Spring.
Создадим интерфейс репозитория и назовем его FileMetadataRepo:
interface FileMetadataRepo : JpaRepository<FileMetadata, Long> {
@Query("select f from FileMetadata f where f.uuid = :fileUUID")
fun findByUuid(fileUUID: UUID) : FileMetadata?
fun deleteByUuid(fileUUID: UUID)
}
В нем мы дополнительно определили две функции: поиск файла по uuid и удаление файла по uuid.
Теперь нам необходимо задать настройки Spring Jpa для того, чтобы он заработал с нашей базой данных PostgreSQL.
Создадим файл application.yml (src/main/resources/application.yml) следующего содержания:
spring:
application:
name: video-streaming-demo
servlet:
multipart:
max-file-size: 10000MB
max-request-size: 10000MB
datasource:
url: jdbc:postgresql://localhost:5432/video-streaming
username: test
password: test
driver-class-name: org.postgresql.Driver
jpa:
hibernate:
ddl-auto: validate
show-sql: true
database: POSTGRESQL
streaming:
chunk:
default-size: 2621440 #-- in bytes
minio:
url: http://localhost:9000
username: minio_admin
password: minio_admin
bucket:
name: videos
stream:
part-size: 5242880 #-- in bytes
Сейчас нас интересуют настройки, связанные с базой данных и jpa. Остальные параметры мы рассмотрим по ходу статьи.
datasource:
url: jdbc:postgresql://localhost:5432/video-streaming
username: test
password: test
driver-class-name: org.postgresql.Driver
jpa:
hibernate:
ddl-auto: validate
show-sql: true
database: POSTGRESQL
Здесь мы указали, какой драйвер будем использовать для подключения к БД, url подключения, имя и пароль пользователя. Обратите внимание, что все эти параметры должны соответствовать тем, что мы указывали в файле docker-compose.yml.
Также мы настроили поведение Hibernate как ddl-auto: validate. Это означает, что движок Hibernate не будет автоматически генерировать объекты в базе данных, в согласии с имеющимися у нас классами-сущностями. Он просто будет проверять их соответствие. Мне такой режим нравится больше, так как дает больше контроля и гибкости над управлением структурой базы данных и позволяет подключить при необходимости системы контроля миграций, такие как Liquibase или Flyway.
Так как для нашего приложения необходима всего лишь одна таблица в базе данных, создадим его вручную.
Подключимся к базе данных и выполним следующий скрипт:
create table if not exists file_meta (
id bigserial primary key,
name varchar (255) not null,
uuid uuid not null unique,
content_type varchar(100) null,
content_size bigint not null,
uploaded_at timestamp not null
);
Готово!
Модель данных, репозиторий для управления моделью, а также таблица в базе данных, соответствующая модели, созданы.
Теперь приступим к следующему шагу - к созданию и настройке клиента для взаимодействия с хранилищем объектов MiniO.
Создание и настройка клиента MiniO
MinIO - это высокопроизводительное объектное хранилище, совместимое с S3.
Концепцию объектного хранилища можно представить себе как некоторое подобие стандартной файловой системы Unix, где есть каталоги и файлы.
В MinIO мы оперируем понятиями "buckets" (вёдра) и "objects" (объекты).
Buckets могут быть вложенными, как и каталоги в Unix, а objects по сути являются нашими файлами.
Для того, чтобы приложение могло подключаться и работать с хранилищем Minio, необходимо создать и настроить клиент.
Создадим класс MinioClientConfig:
package ru.tuneit.videostreamingdemo.integrations.s3
import io.minio.MinioClient
import org.springframework.beans.factory.annotation.Value
import org.springframework.context.annotation.Bean
import org.springframework.context.annotation.Configuration
@Configuration
class MinioClientConfig (
@Value("\${minio.url}") val minioUrl: String,
@Value("\${minio.username}") val minioUsername: String,
@Value("\${minio.password}") val minioPassword: String) {
@Bean
fun generateMinioClient(): MinioClient {
return try {
MinioClient.builder()
.endpoint(minioUrl)
.credentials(minioUsername, minioPassword)
.build()
} catch (e: Exception) {
throw RuntimeException(e.message)
}
}
}
Также нам необходимо создать сервис для выполнения операций с хранилищем (сохранение объекта в хранилище, получение его содержимого, удаление объекта).
Создадим класс MinioService:
package ru.tuneit.videostreamingdemo.integrations.s3
import io.minio.*
import jakarta.annotation.PostConstruct
import org.springframework.beans.factory.annotation.Value
import org.springframework.stereotype.Service
import org.springframework.web.multipart.MultipartFile
import ru.tuneit.videostreamingdemo.model.FileMetadata
import java.io.InputStream
import java.util.UUID
import kotlin.system.exitProcess
@Service
class MinioService (
@Value("\${minio.bucket.name}")
val bucketName: String,
@Value("\${minio.stream.part-size}")
val streamPartSize: Long,
val minioClient: MinioClient
) {
@PostConstruct
fun initialize() {
if (!bucketExists()) createBucket()
}
private fun bucketExists(): Boolean {
return runCatching { minioClient.bucketExists(BucketExistsArgs.builder().bucket(bucketName).build()) }
.getOrDefault(false)
}
private fun createBucket() {
val args = MakeBucketArgs.builder()
.bucket(bucketName)
.build()
runCatching { minioClient.makeBucket(args)}
.onFailure { exitProcess(1) }
}
fun uploadFile(file: MultipartFile, fileMetadata: FileMetadata) {
minioClient.putObject(
PutObjectArgs
.builder()
.bucket(bucketName)
.`object`(fileMetadata.uuid.toString())
.stream(file.inputStream, file.size, streamPartSize)
.build()
)
}
fun deleteFile(fileUUID: UUID) {
minioClient.removeObject(
RemoveObjectArgs.builder()
.bucket(bucketName)
.`object`(fileUUID.toString())
.build())
}
fun getFileAsInputStream(fileMetadata: FileMetadata, offset: Long, length: Long): InputStream {
return minioClient.getObject(
GetObjectArgs
.builder()
.bucket(bucketName)
.offset(offset)
.length(length)
.`object`(fileMetadata.uuid.toString())
.build()
)
}
}
Обратите внимание на свойства в этих классах, помеченные аннотацией @Value. Значения этих свойств подставляются из файла application.yml:
minio:
url: http://localhost:9000
username: minio_admin
password: minio_admin
bucket:
name: videos
stream:
part-size: 5242880 #-- in bytes
В сервисе нам особо интересны две функции: uploadFile и getFileAsInputStream. Первая используется для сохранения файла в хранилище. Обратите внимание, что мы используем в ней метод stream и передаем в него параметр streamPartSize. Это необходимо для контроля использования памяти, так как в этом случае, клиент MiniO будет сохранять наш файл в хранилище не целиком сразу, а кусочек за кусочком. Вторая функция используется для получения объекта из хранилища в форме InputStream. Важной деталью здесь является то, что когда мы запрашиваем InputStream нашего объекта, мы передаем значения смещения (offset) и длины (length). Это позволяет нам получать видео небольшими частями.
И так, мы создали и настроили клиент хранилища объектов Minio, запрограммировали сервис для взаимодействия с этим хранилищем.
Сейчас давайте приступим к реализации слоя приложения, в котором будет содержаться бизнес логика - к сервису потокового видео.
Создание сервиса потокового видео
Я намеренно пропустил этот раздел. В тот день, когда я писал эту статью, на меня напала лень. Захотелось дать вам задание для самостоятельного изучения. А еще захотелось, чтобы вы зашли на мой GitHub и посмотрели код этого проекта целиком ;) Поэтому, исходный код этого сервиса вы сможете найти здесь в моем GitHub.
p.s. спасибо, что разделяете мое чувство юмора :)
Создание контроллера и эндпоинтов
Для того, чтобы пользователи могли взаимодействовать с нашим приложением через http запросы, создадим контроллер и в нём несколько базовых эндпоинтов.
Назовем класс контроллера VideoStreamingController. Вот его содержимое:
@RestController
@RequestMapping("/streaming/video")
class VideoStreamingController (
val videoStreamingService: VideoStreamingService,
@Value("\${streaming.chunk.default-size}") val chunkDefaultSize: Long
) {
@GetMapping("/{uuid}")
fun fetchChunk(
@RequestHeader(value = RANGE, required = false) range: String?,
@PathVariable uuid: UUID
): ResponseEntity<ByteArray?> {
val parsedRange = StreamRange.parseHttpRangeString(range, chunkDefaultSize)
val streamChunk = videoStreamingService.fetchChunk(uuid, parsedRange)
return ResponseEntity.status(HttpStatus.PARTIAL_CONTENT)
.header(CONTENT_TYPE, streamChunk.fileMetadata.contentType)
.header(ACCEPT_RANGES, "bytes")
.header(CONTENT_LENGTH, getContentLengthHeader(parsedRange, streamChunk.fileMetadata.contentSize))
.header(CONTENT_RANGE, getContentRangeHeader(parsedRange, streamChunk.fileMetadata.contentSize))
.body(streamChunk.chunk)
}
@GetMapping("/list")
fun getVideoList(): List<FileMetadata> = videoStreamingService.getVideoList()
@PostMapping("/upload")
fun saveVideo(
@RequestParam("video") video: MultipartFile,
@RequestParam("videoName") videoName : String)
= ResponseEntity.ok(videoStreamingService.saveVideo(video, videoName))
@PostMapping("/delete/{uuid}")
fun deleteVideo(@PathVariable uuid: UUID) = ResponseEntity.ok(videoStreamingService.deleteVideo(uuid))
private fun getContentLengthHeader(range: StreamRange, fileSize: Long)
= (range.getRangeEnd(fileSize) - range.rangeStart + 1).toString()
private fun getContentRangeHeader(range: StreamRange, fileSize: Long)
= "bytes " + range.rangeStart + "-" + range.getRangeEnd(fileSize) + "/" + fileSize
}
С помощью аннотации @RequestMapping("/streaming/video") мы задали правило обработки запросов таким образом, что если запрос поступает по адресу "/streaming/video", то он обрабатывается нашим контроллером.
В контроллере, мы создали четыре базовых эндпоинта:
1) Для получения порции данных видеопотока. Доступен через GET запрос по адресу "/streaming/video/{uuid}".
2) Для получения метаданных всех загруженных видео в виде списка. Доступен через GET запрос по адресу "/streaming/video/list".
3) Для загрузки видео в сервис. Доступен через POST запрос по адресу "/streaming/video/upload".
4) Для удаления видео из сервиса. Доступен через POST запрос по адресу "/streaming/video/delete/{uuid}".
Рассмотрим первый и третий эндпоинты более подробно.
Первый эндпоинт, реализованный в функции fetchChunk, принимает на вход два параметра, - обязательный @PathVariable "uuid" - уникальный идентификатор файла и необязательный @RequestHeader(value = RANGE, required = false) "range" - диапазон запрашиваемого контента в байтах, который передается как http header "RANGE".
Логика функции реализована следующим образом: сначала мы пытаемся разобрать диапазон получаемого контента из переданного header "RANGE", затем обращаемся в наш сервис потокового видео и получаем порцию видео, соответствующую этому диапазону, и, наконец, мы формируем и отдаем в качестве ответа ResponseEntity со всеми необходимыми заголовками и телом, содержащим кусочек видео.
Статус ответа и заголовки в нём следующие:
status — Http 206 status code (Partitial Content, часть содержимого/контента)
заголовок ACCEPT_RANGES — сообщает какой тип диапазона поддерживает и ожидает наш сервис. В нашем случае это - "bytes".
заголовок CONTENT_LENGTH — размер порции данных, который мы собираемся отправить клиенту, в байтах
заголовок CONTENT_RANGE — диапазон (начало и конец включительно) порции данных, которую мы извлекли на основе переданного заголовка Range, в байтах
Третий эндпоинт, реализованный с помощью функции saveVideo принимает на вход два обязательных параметра: "video" типа MultipartFile - сам видео файл и строковый "videoName" - название видео.
Функция передает полученные данные в сервис потокового видео, который в свою очередь сохраняет видео файл в хранилище объектов, а также генерирует и сохраняет его метаданные в базу данных, возвращая при этом уникальный идентификатор UUID файла. Этот идентификатор, который далее может быть использован в других эндпоинтах нашего приложения, мы отдаем клиенту в качестве ответа.
На этом моменте мы рассмотрели все основные моменты как устроено и реализовано наше приложение. Давайте теперь проверим его работу в действии.
Запуск и тестирование приложения
Для старта нашего Spring Boot приложения можно нажать на кнопку run или debug в Intellij IDEA или же запустить jar-файл с нашим приложением.
Для начала давайте загрузим пару видео в наш сервис. Для тестирования я скачал несколько бесплатных видео просто из интернета. Их я и буду загружать.
Для взаимодействия с приложением я буду использовать клиент Postman. Вы можете использовать любой другой, который вам по душе.
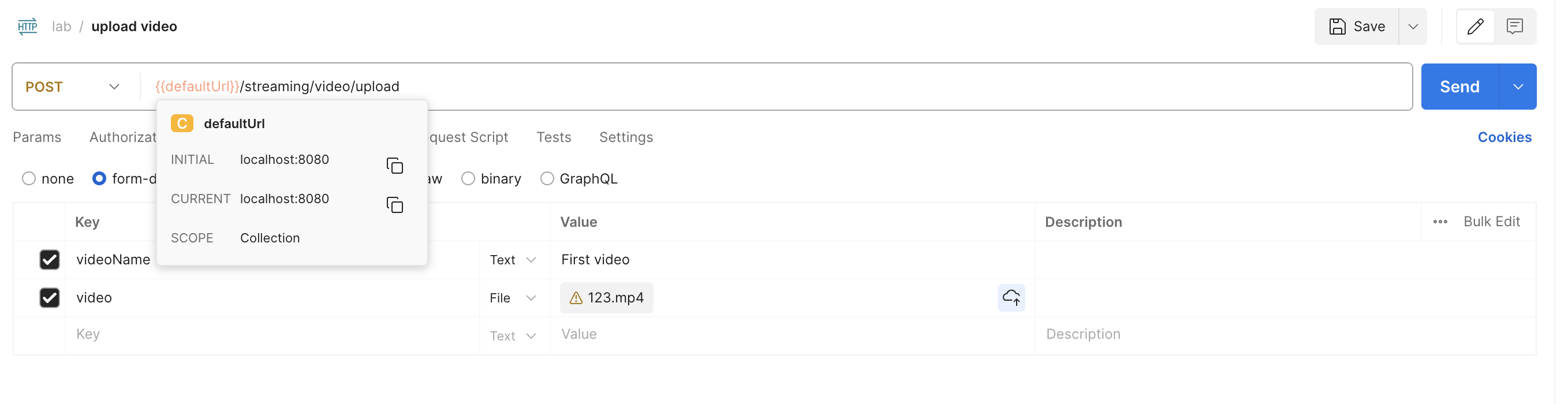
Задаем название видео, прикрепляем само видео (через параметры в разделе Body -> form-data) и нажимаем на кнопку Send.
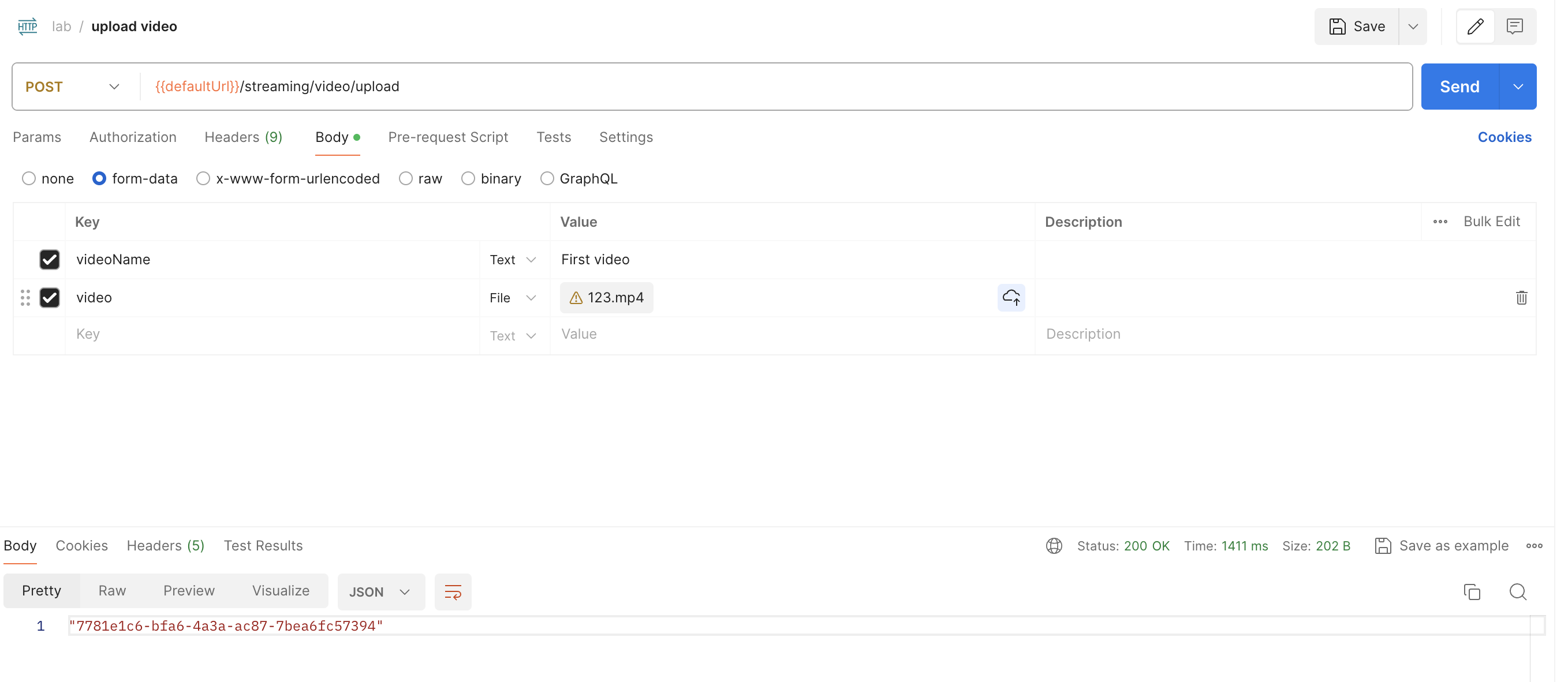
Видим, что эндпоинт отдал нам уникальный uuid загруженного файла.
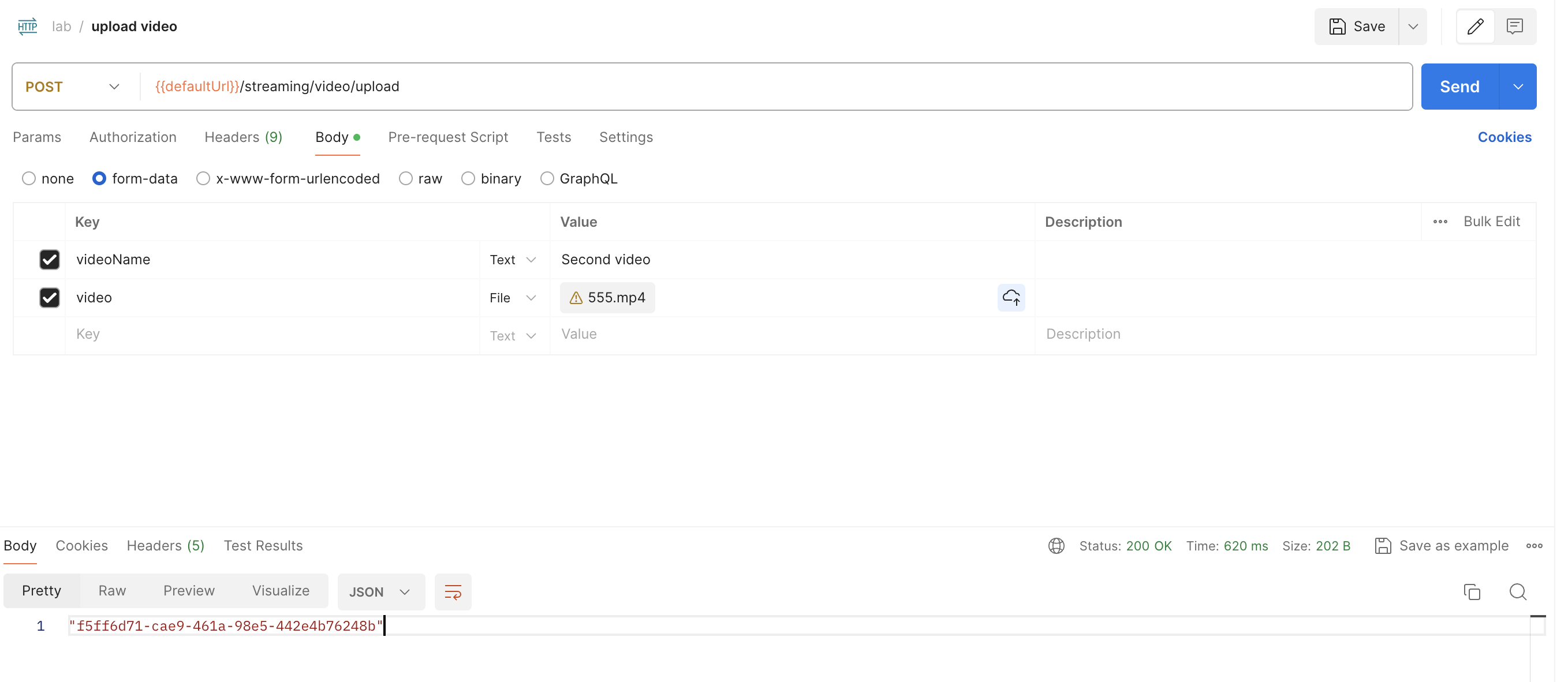
Повторим тоже самое со вторым видео.
Так выглядит содержимое таблицы с метаданными файлов в БД после успешной загрузки двух видео:

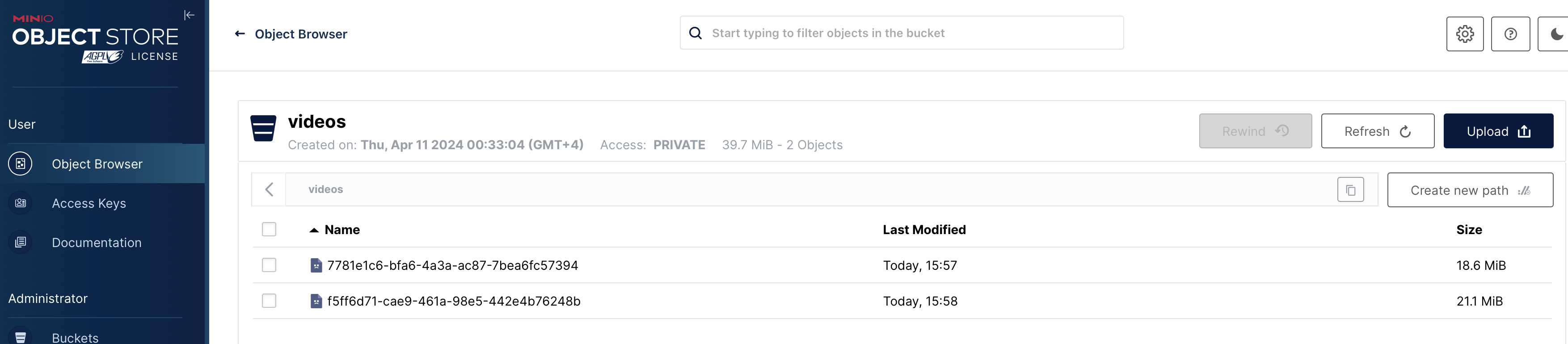
А так выглядит содержимое бакета в Minio:
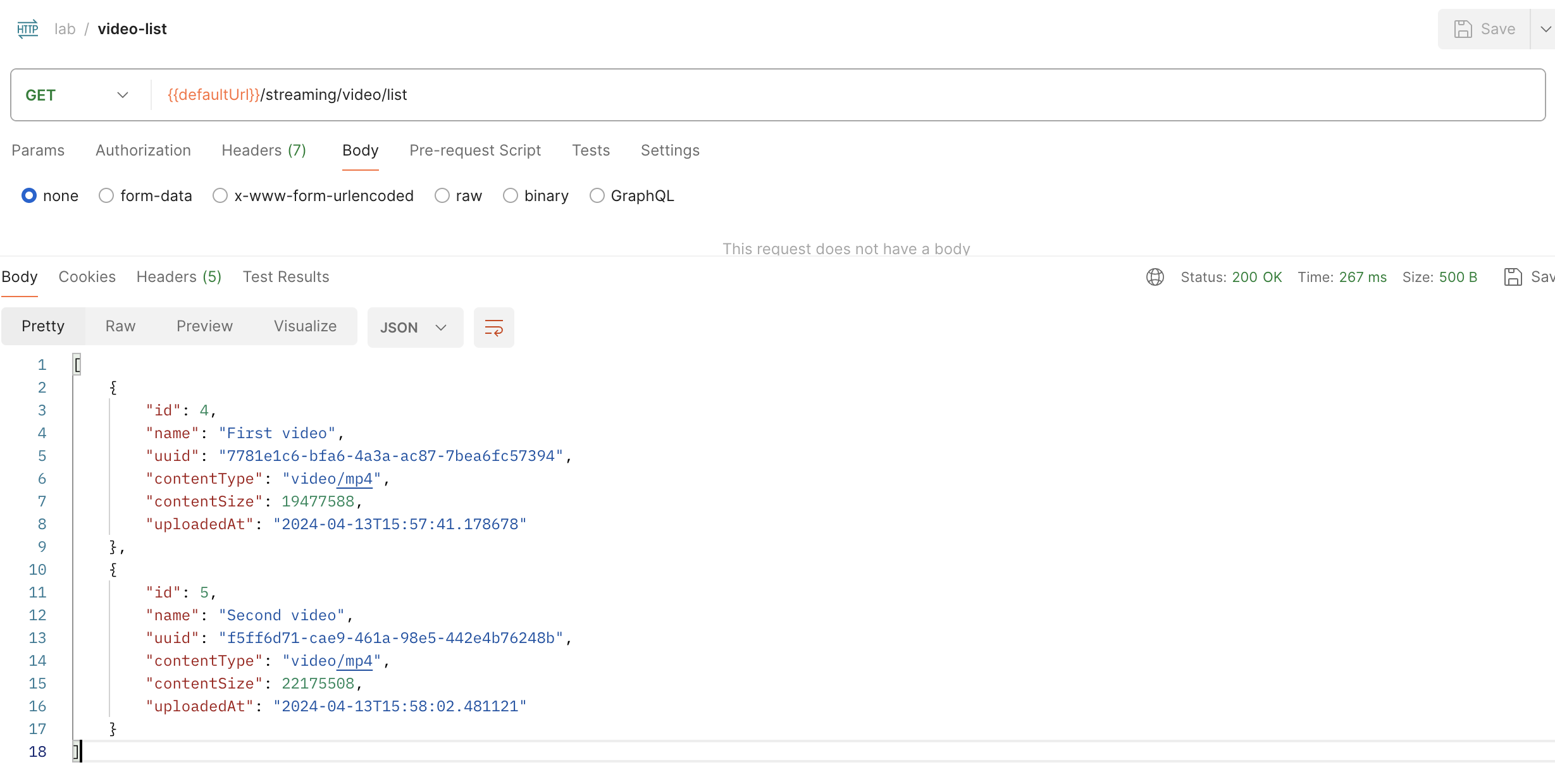
Теперь давайте попробуем обратиться к эндпоинту, который покажет нам список загруженных в наш сервис файлов с их метаданными:
Используя сгенерированные сервисом уникальные uuid файлов, давайте попробуем воспроизвести наши видео в потоковом режиме.
Первое видео запросим через Postman, а второе - через любой современный браузер. Я буду использовать Mozilla.
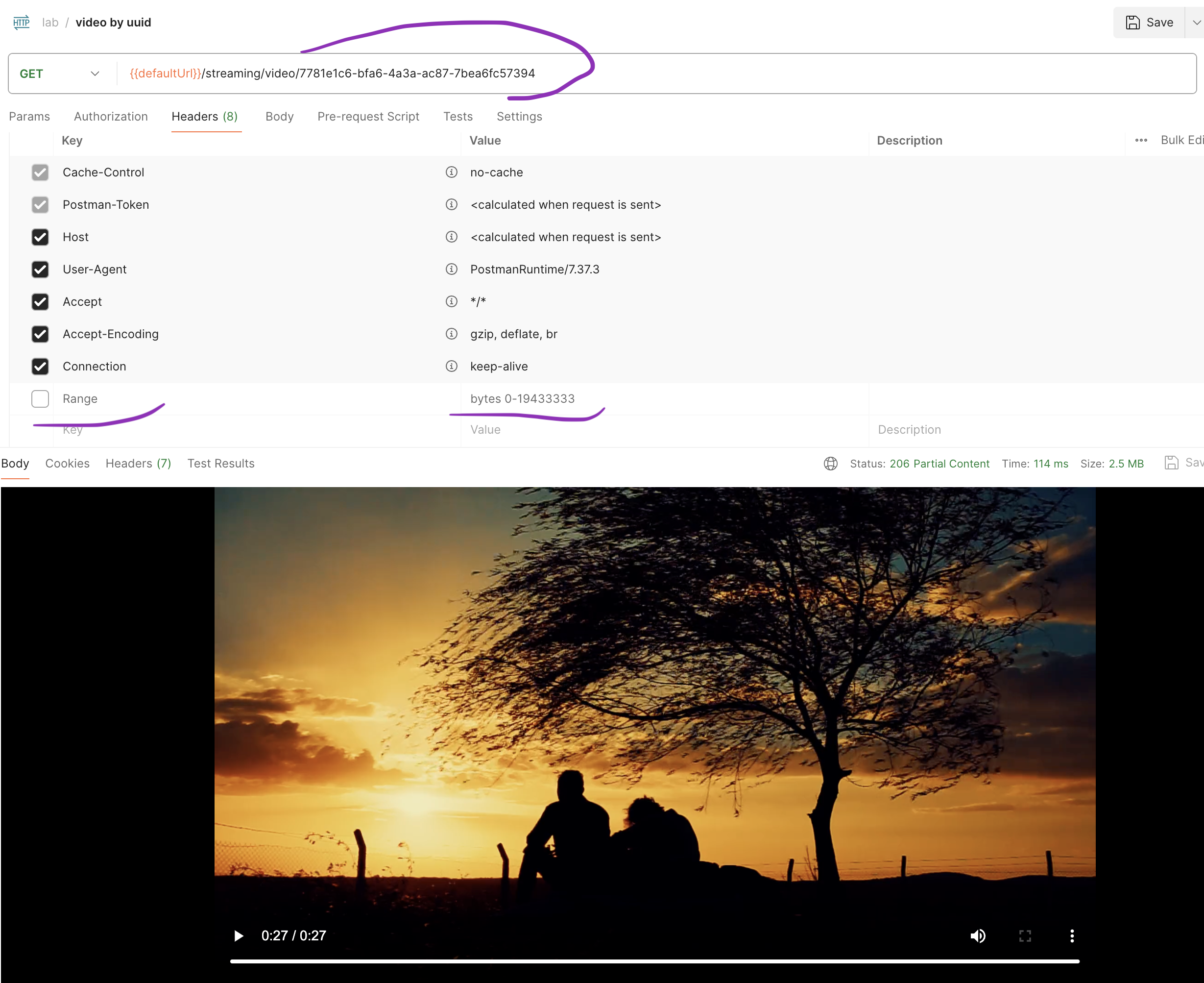
Обратите внимание, что мы можем вручную задать необходимый диапазон контента в байтах, который мы желаем получить, указав этот диапазон в заголовке "Range". В нашем случае, если мы укажем Range = bytes 0-19433333, то получим кусочек видео в диапазоне с нуля до примерно 19.4 Мбайт. Если мы хотим к примеру получить кусочек видео с его середины и до конца, то тогда можем указать Range = bytes 9738793-19477587
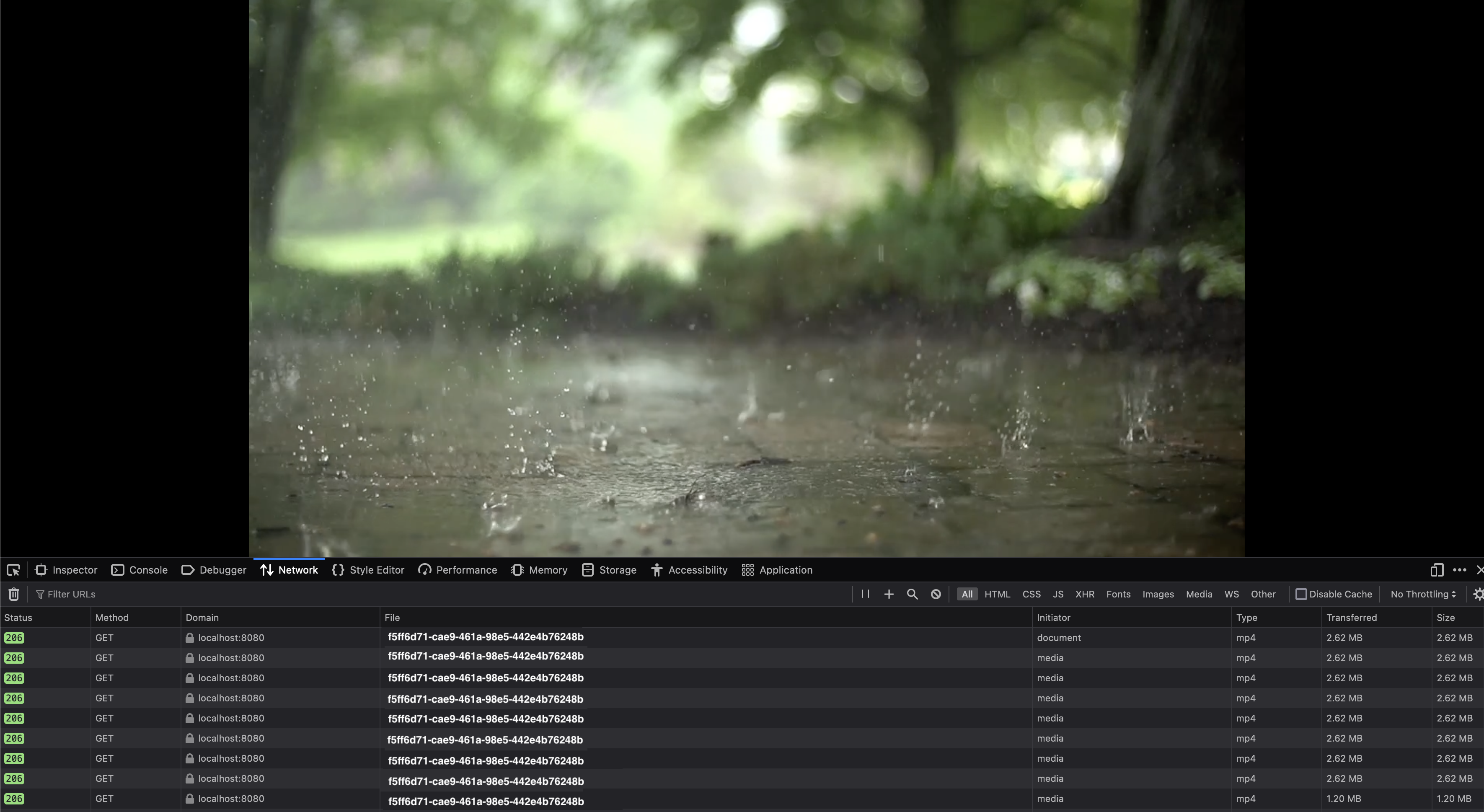
В браузере видео также производится в потоковом режиме без каких-либо проблем.
localhost:8080/streaming/video/f5ff6d71-cae9-461a-98e5-442e4b76248b
Наконец, давайте попробуем удалить видео из нашего сервиса, обратившись к соответствующему эндпоинту:
После вызова этого эндпоинта, проверим список загруженных файлов:
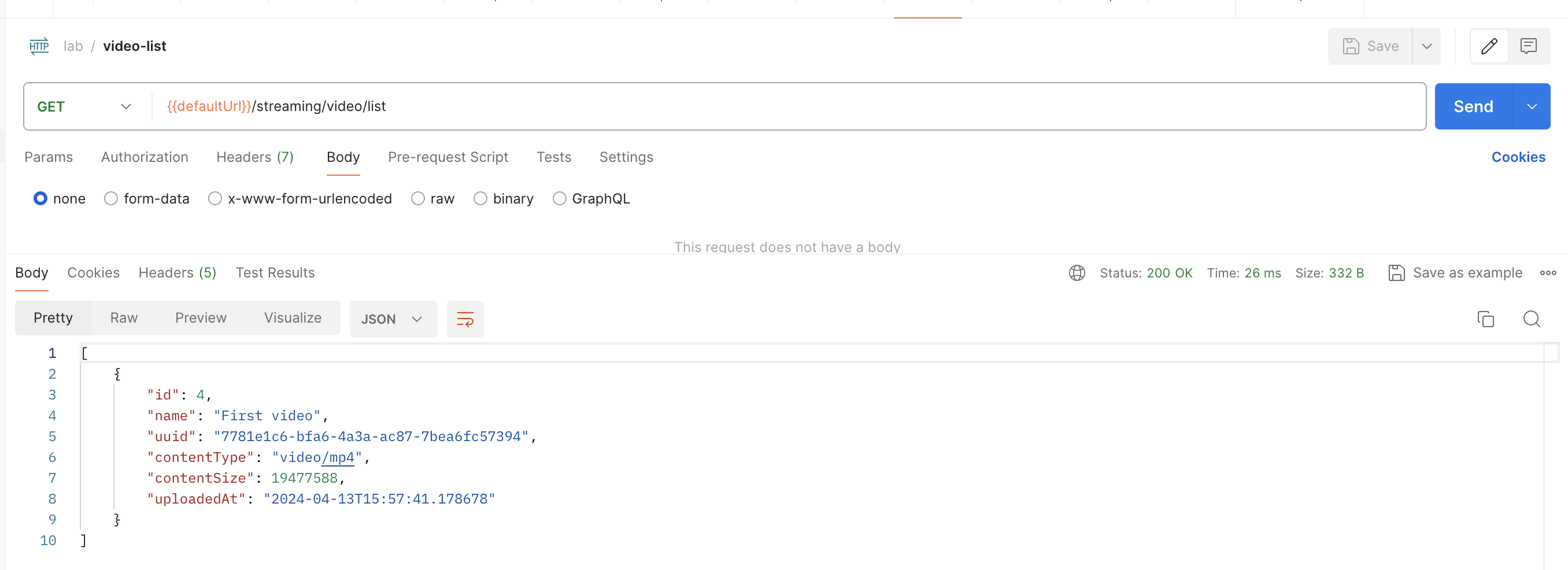
Да, видим, что осталось только одно видео из двух.
Превосходно! Мы успешно протестировали наше приложение и убедились, что весь функционал работает так как нужно.
Вместо заключения
Большое спасибо что прочитали эту статью! В наших блогах вы сможете найти еще много интересного и полезного. Добро пожаловать :)
Полный исходный код этой статьи вы сможете найти здесь в моем GitHub.

