Данная заметка относится к размышлениям, последовательным, логически связанным, и хочется продолжить базовым и очевидным.... НО НЕТ!
К сожалению, не очевидным повсеместно для ИТ специалистов.
Обычно, в блоге мы пишем о "тонких" случаях демонстрации нашей квалификации с некоторой высоты нашего опыта и компетенций. Но в данной заметке, разложу вещи, которые в моём понимании должен базово осознавать и использовать любой средний(!!!) ИТ-инженер (девопс, айтиопс, сисадмин и прочие синонимы).
Обозначу проблему:
чудным понятием "Кластер" или "узел" - прим. зависит от архитектуры - покрывают задачу обеспечения непрерывности работы ИТ сервиса/приложения/системы.
И это было бы правильно, если бы учитывалась многоуровневость!
Увы,
"Ну у нас vmWare кластер, общее хранилище, всё у нас отказоустойчиво".
Нет.
Для критически важных систем (ИТ-сервисов) к которым применяется требование по непрерывности функционирование (попросту простой недопустим) помимо обеспечения отказоустойчивости
- на физическом уровне (в т.ч по отказу серверной),
- сетевой доступности,
- уровне виртуальной машины,
- уровне приложений
Необходимо организовывать схему с
- Active-active или active-passive кластера приложений и данных с автоматическим переключением внутри экземпляров виртуальных машин
- Дополнительные passive экземпляры зеркала с автоматическим или ручным переключением.
Вспомним хотя бы классический стек ИТ, например, в представлении Sun/Oracle и увидим, что одним решением, вернее решением на ОДНОМ уровне не отделаться:
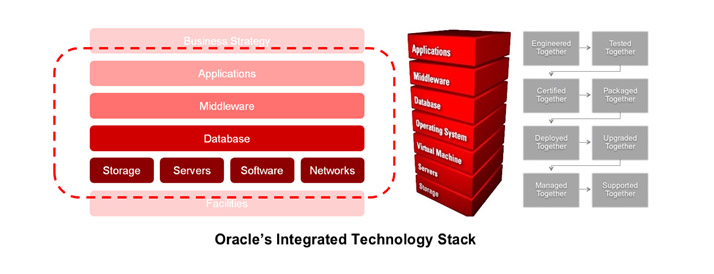
И если мы говорим об отказоустойчивости, читайте высокой ДОСТУПНОСТИ, приложения Application, что наверху стека, позаботиться стоит об отработке отказа, масштабировании и роутинге запросов (не сугубо сетевом) на каждом из уровней. См. ITOps.
Выбор тех или иных вендорских или opensource технологий и платформ принципиально не играет роли при рассмотрении данного вопроса - концептульной АРХИТЕКТУРЫ отказоустойчивости ИТ-системы.
Отказоустойчивость и высокая доступность
Схема для компонента критического ИТ сервиса на примере ниже.
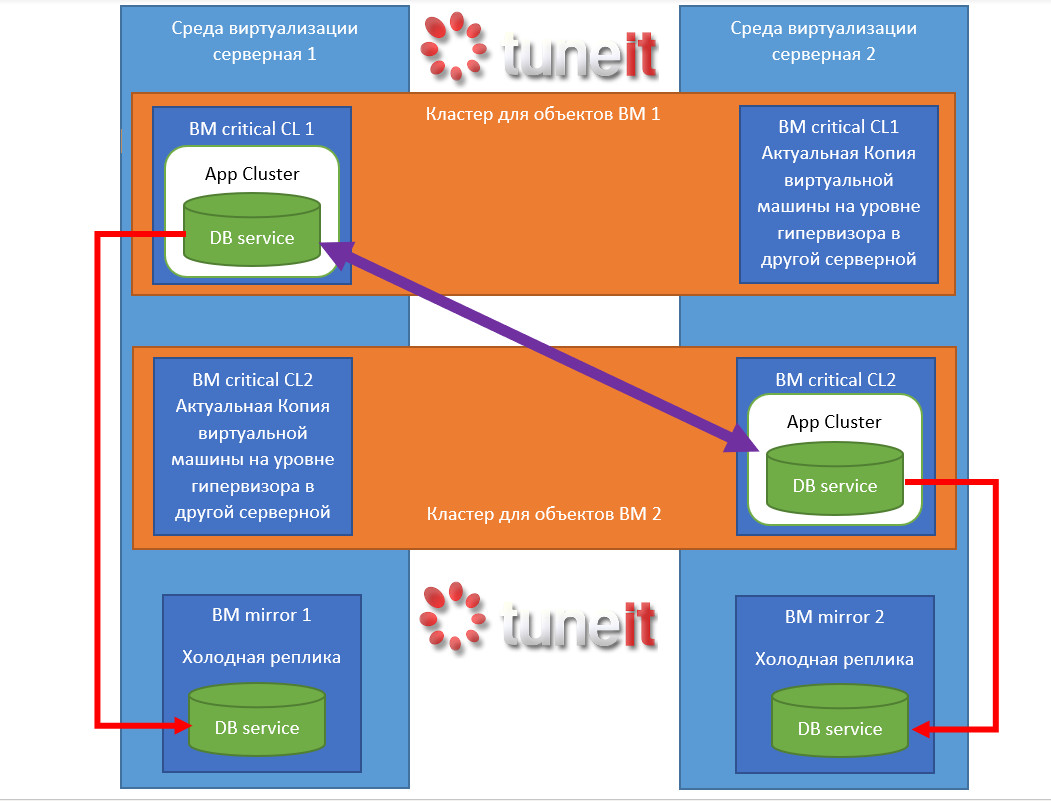
Заметьте, здесь не отделаться "одним кластером гипервизора". Кластер гипервизора покрывает объекты виртуальных машин. Но виртуальная машина не покрывает рисков ниже - сбой выполнения на оборудовании/сети и выше - сбой приложения, операционной системы.
Разберем архитектуру подробно в живую.
В примере показано, как 1 IT service DB Сервис (для примера) выполняется на ВМ Critical CL1 на Среде виртуализации серверная 1 в рамках кластера для приложения App cluster внутри гостевой ОС ВМ Critical CL1 (прим.в некоторых приложениях возможно реализовать как кластеризацию их средствами, так и распределенную структуру, но концепции примера это не меняет).
Виртуальная машина защищена по данным и на уровне гипервизора по выходу из строя серверной копия находится ВМ Critical CL1 в Среде виртуализации серверная 2.
Тем не менее, такая схема описанная до этого момента не обеспечивала бы покрытие на уровне по данным приложения и по сбою приложения (сбой приложения внутри ОС также бы отразился на реплику виртуальной машины).
Для защиты на уровне приложения его реплика на уровне кластера App cluster (или приложения, см. примечание выше) находится на параллельно функционирующей ВМ Critical CL1 виртуальной машине ВМ Critical CL2, также покрытой по непрерывности работы на уровне гипервизора, массивов данных , но с отличием, что активная копия находится в другой серверной Среде виртуализации серверная 2.
В случае сбоя на уровне ВМ среда виртуализации готова переключить/поднять ВМ Critical CL2 с кластером и приложением в Среде виртуализации серверная 1.
Для защиты по данным и в случае краха кластера и приложений в каждой из сред виртуализации находятся зеркальные (пассивные) копии вне кластеров, куда данные от сервисов приходят ассинхронно.
В случае сбоя кластера остается возможность вручную или автоматически поднять пассивную копию сделав её основной до устранения проблем с основной связкой. После устранения перенастроить репликацию обратно – чтобы новые данные с временно работающих систем перешли на основную починенную связку и после произвести переключение.
Зеркальные системы также могут быть включены в кластера на уровне гипервизора, а не быть отдельными экземплярами для каждой из серверных как в примере.
Предложенный пример показывает и минус данной архитектуры – избыточность по потреблению ресурсов серверов и систем хранения данных.
Во избежание Split Brain возможно установка дополнительных quorum устройств, но это уже детали реализации.
И где-то рядом, идёт проработка обособленных процессов и задач резервного копирования и восстановления данных....
За
- поддержкой,
- обучением технологиям ИТ,
- ITOps и DevOps услугами,
- построением архитектуры ИТ,
- и консультациями,
- в том числе по организации процессов качественной поддержки ИТ (ITIL,ITSM)
, смело обращайтесь к нам в Tune-IT!

